
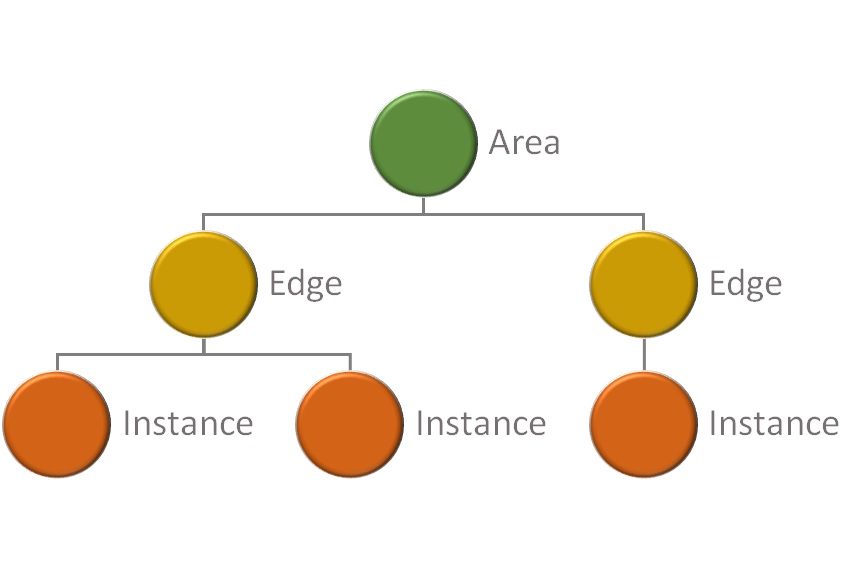
What is an Edge Intelligence network?
An Edge Intelligence network provides a geographically distributed data lake and comprises of multiple data collectors running on distributed edge servers in different locations all operating, managed and accessed as a single logical database.
Each collector gathers and stores data created locally to it and allows the data to remain at source to avoid the restrictions and technical limitations imposed by shipping bulk data over public networks to a single database. For example, network bandwidth may limit the volume of data that shipped; or the data may be too sensitive to be moved off-premise; or there may be geo-political reasons why the data cannot cross borders.
However, users connect to a network and perform queries as though all of the data were in one central database.
A network can be used to implement a hybrid cloud for data storage and analytics where some of the servers are on-premise and others are hosted in cloud data centres.
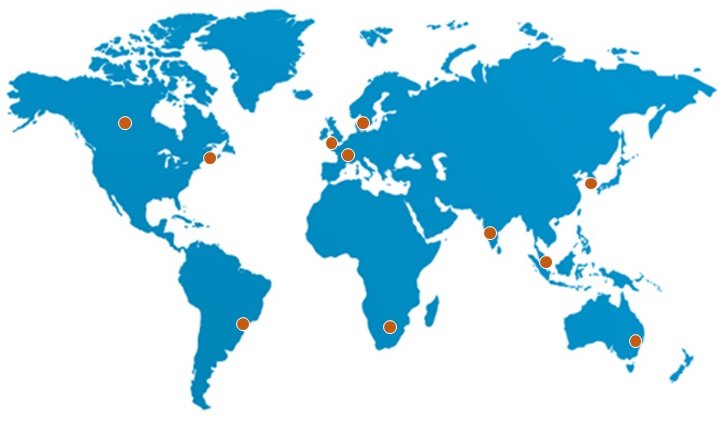
Topologies
Each collector is a leaf node in a tree of logical nodes where the depth and shape of the tree can be arranged as required. For example, collectors may be distributed over various global locations and these can be grouped under nodes that represent different continents, countries or regions in any arbitrary hierarchy.
The topology of a network can reflect logical and/or spatial relationships between the data stored by collectors.
At query time, queries can be submitted in the context of a node in the network - such as the root node of the whole network; or a node that denotes a particular region of the network; or a node that denotes an edge point. Hence users are able to perform analysis across the network as a whole or within chosen areas of the networks.
The shape and composition of a network is managed centrally and can be dynamically changed, where any changes to the network take immediate effect.
Schemas
Each network contains one or more schemas, where each schema is a collection of database objects such as tables, views and functions. All objects are managed centrally and can be dynamically changed, where any changes take immediate effect. Hence, schemas are agile and can be changed at will to meet the demands of evolving requirements as and when they occur. There is no need to "see around the corner" or make decisions with long-term consequences.
Even though a schema is relational, it is agile and dynamic enough to be considered almost schema-less.
Data
Each collector in a network can acquire messages from local data sources such as gateways, devices, probes or brokers and may be received in a variety of formats such as JSON with messages recorded as rows in tables and immediately available to SQL queries.
The parsing of messages and the mapping of message content to relational tables is defined and managed centrally and can be dynamically changed. For example, the values associated with specific keys in a JSON message can be mapped to specific columns in a table.
Data which is universally common across a network, such as dimension or reference data is defined and managed centrally too. For example, rows in a dimension table can be inserted, updated or deleted as required and those changes become immediately effective for queries performed in the network.
Comments
Article is closed for comments.